Generating images of rare concepts using pre-trained diffusion models
AAAI 2024
Dvir Samuel , Rami Ben-Ari, Simon Raviv, Nir Darshan and Gal Chechik
Norm-guided latent space exploration for text-to-image generation
NeurIPS 2023
Dvir Samuel , Rami Ben-Ari, Nir Darshan, Haggai Maron and Gal Chechik
Abstract
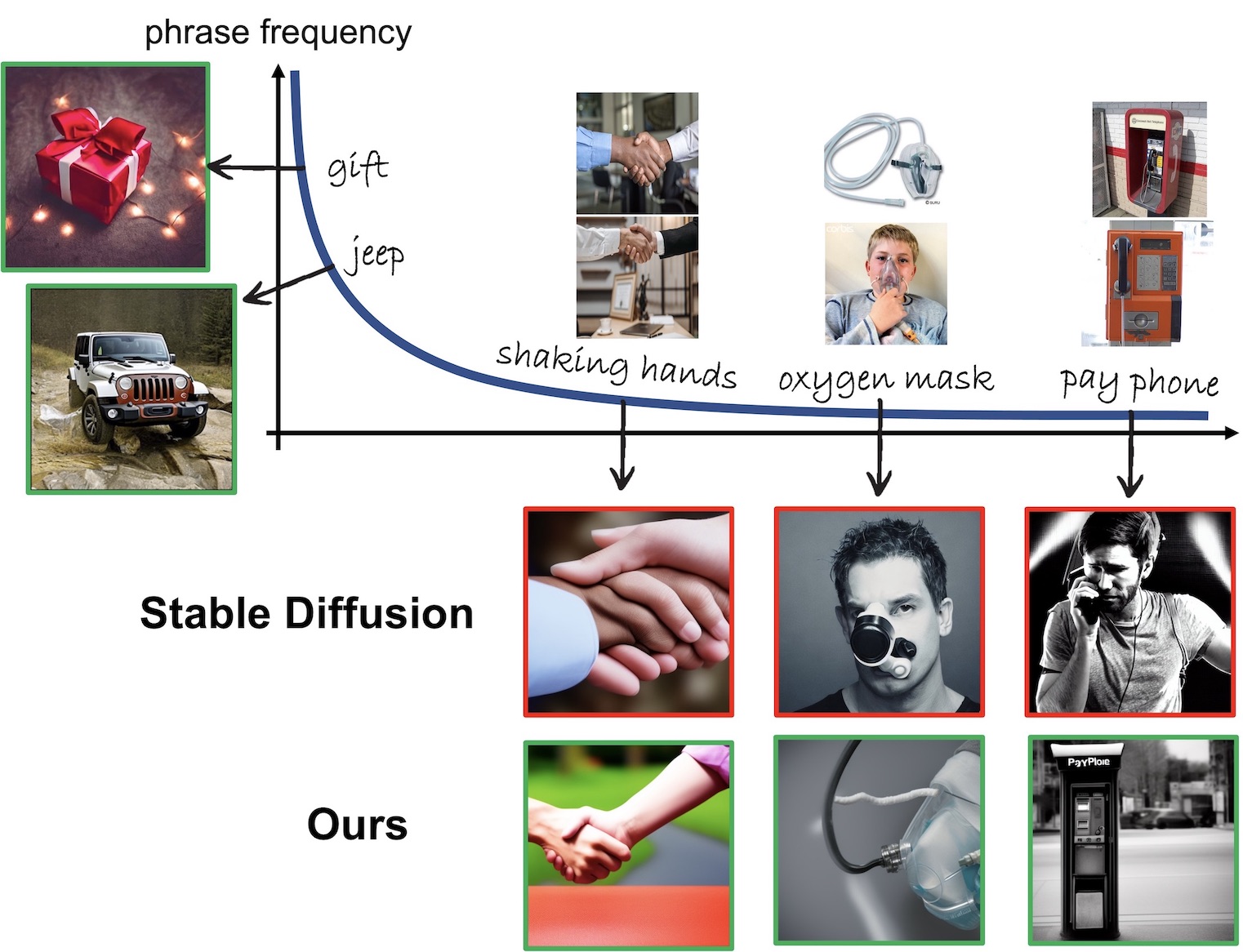
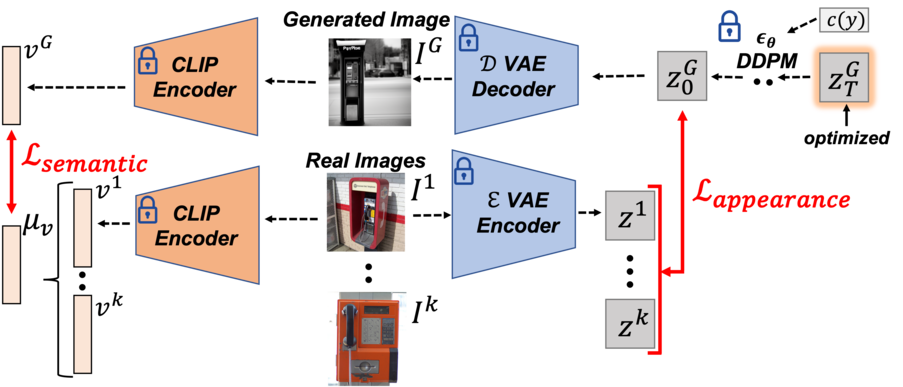
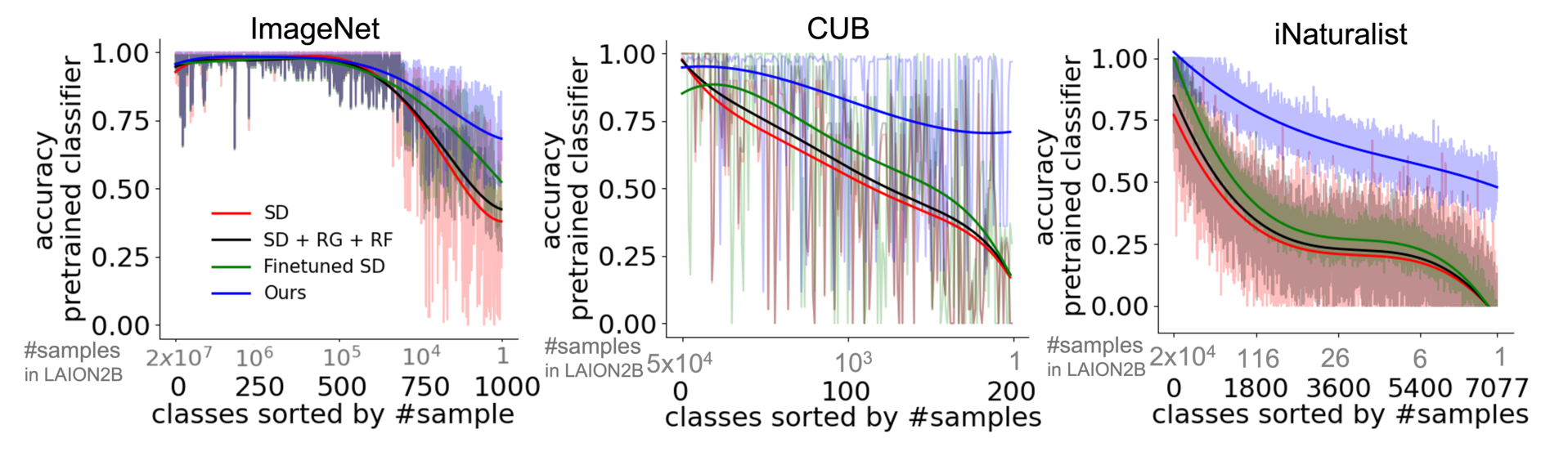
Text-to-image diffusion models can synthesize high-quality images, but they have various limitations. Here we highlight a common failure mode of these models, namely, generating uncommon concepts and structured concepts like hand palms. We show that their limitation is partly due to the long-tail nature of their training data: web-crawled data sets are strongly unbalanced, causing models to under-represent concepts from the tail of the distribution. We characterize the effect of unbalanced training data on text-to-image models and offer a remedy. We show that rare concepts can be correctly generated by carefully selecting suitable generation seeds in the noise space, using a small reference set of images, a technique that we call SeedSelect. SeedSelect does not require retraining or finetuning the diffusion model. We assess the faithfulness, quality and diversity of SeedSelect in creating rare objects and generating complex formations like hand images, and find it consistently achieves superior performance. We further show the advantage of SeedSelect in semantic data augmentation. Generating semantically appropriate images can successfully improve performance in few-shot recognition benchmarks, for classes from the head and from the tail of the training data of diffusion models.

Cite our paper
@inproceedings{Samuel2023SeedSelect,
title={Generating images of rare concepts using pre-trained diffusion models},
author={Dvir Samuel and Rami Ben-Ari and Simon Raviv and Nir Darshan and Gal Chechik},
year={2024},
journal={AAAI}}

Abstract
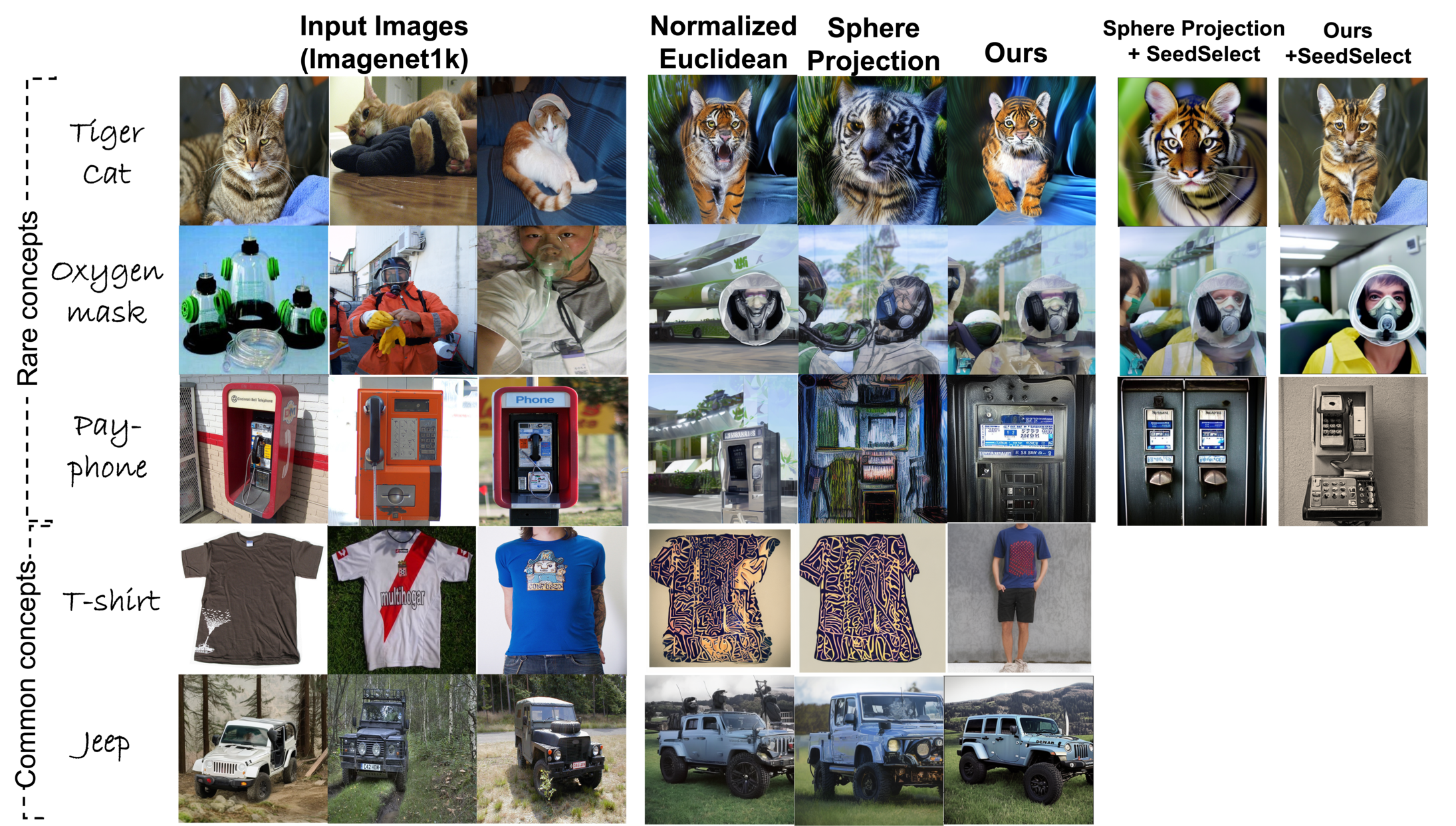
Text-to-image diffusion models show great potential in synthesizing a large variety of concepts in new compositions and scenarios. However, their latent seed space is still not well understood and has been shown to have an impact in generating new and rare concepts. Specifically, simple operations like interpolation and centroid finding work poorly with the standard Euclidean and spherical metrics in the latent space. This paper makes the observation that current training procedures make diffusion models biased toward inputs with a narrow range of norm values. This has strong implications for methods that rely on seed manipulation for image generation that can be further applied to few-shot and long-tail learning tasks. To address this issue, we propose a novel method for interpolating between two seeds and demonstrate that it defines a new non-Euclidean metric that takes into account a norm-based prior on seeds. We describe a simple yet efficient algorithm for approximating this metric and use it to further define centroids in the latent seed space. We show that our new interpolation and centroid evaluation techniques significantly enhance the generation of rare concept images. This further leads to state-of-the-art performance on few-shot and long-tail benchmarks, improving prior approach in terms of generation speed, image quality, and semantic content.


Cite our paper
@inproceedings{Samuel2023NAO,
title={Norm-guided latent space exploration for text-to-image generation},
author={Dvir Samuel and Rami Ben-Ari and Nir Darshan and Haggai Maron and Gal Chechik},
year={2023},
journal={NeurIPS}}