Learning Object Permanence From Video
Accepted to ECCV, 2020
Aviv Shamsian , Ofri Kleinfeld , Amir Globerson , Gal Chechik
Video
Abstract
Object Permanence allows people to reason about the location of non-visible objects, by understanding that
they continue to exist even when not perceived directly. Object Permanence is critical for building a model
of the world, since objects in natural visual scenes dynamically occlude and contain each-other. Intensive
studies in developmental psychology suggest that object permanence is a challenging task that is learned
through extensive experience.
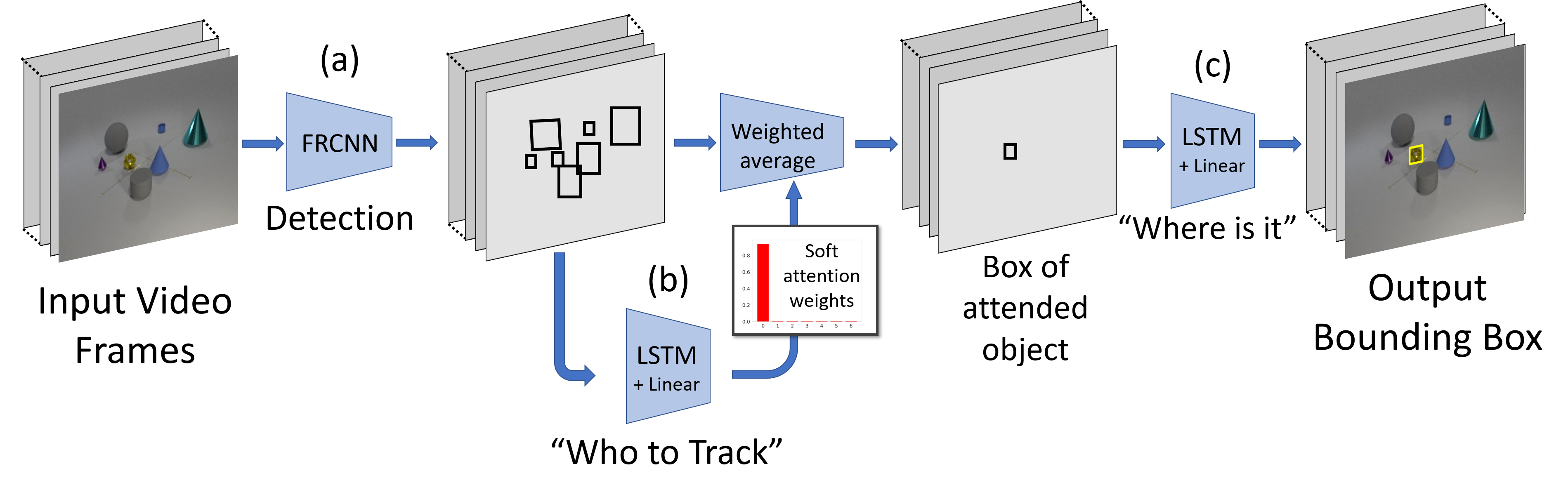
We introduce three main novel contributions:
(1) Conceptualizing that localizing non-visible objects
requires two types of reasoning: about occluded objects and about carried ones.
(2) define four subtypes of localization tasks and introduce annotations for the CATER dataset to facilitate evaluating each of these
subtasks.
(3) We describe a new unified architecture (OPNet) for all four subtasks, which can capture the
two types of reasoning.
Cite our paper
@article{shamsian2020learning, title={Learning Object Permanence from Video}, author={Shamsian, Aviv and Kleinfeld, Ofri and Globerson, Amir and Chechik, Gal}, journal={arXiv preprint arXiv:2003.10469}, year={2020} }